Introdução: no universo das ferramentas de SEO, a concorrência é acirrada. Muitos detratores, colegas, concorrentes avançam sobre os métodos, tecnologias utilizadas pela plataforma SEOQuantum sem conhecer nossos algoritmos. Este artigo revela uma parte do nosso segredo industrial. Aproveite :-)
Criar conteúdos de qualidade e relevantes em relação às palavras-chave nas quais você deseja se classificar é essencial. A relevância do conteúdo, por sua vez, é mais difícil de avaliar. O tempo em que se podia enganar um motor de busca fazendo-o acreditar que o conteúdo estava relacionado a um tópico, preenchendo as páginas e as tags com o máximo de palavras-chave, coocorrências e sinônimos possíveis, acabou.
O Google está constantemente melhorando sua capacidade de entender o comportamento humano e a linguagem. A capacidade do motor de busca de entender e analisar as intenções de busca dos usuários é melhor do que nunca. Portanto, é essencial melhorar nossa capacidade de medir a relevância para poder criar um conteúdo que o Google perceba como realmente útil e, portanto, mais digno de ser bem referenciado.
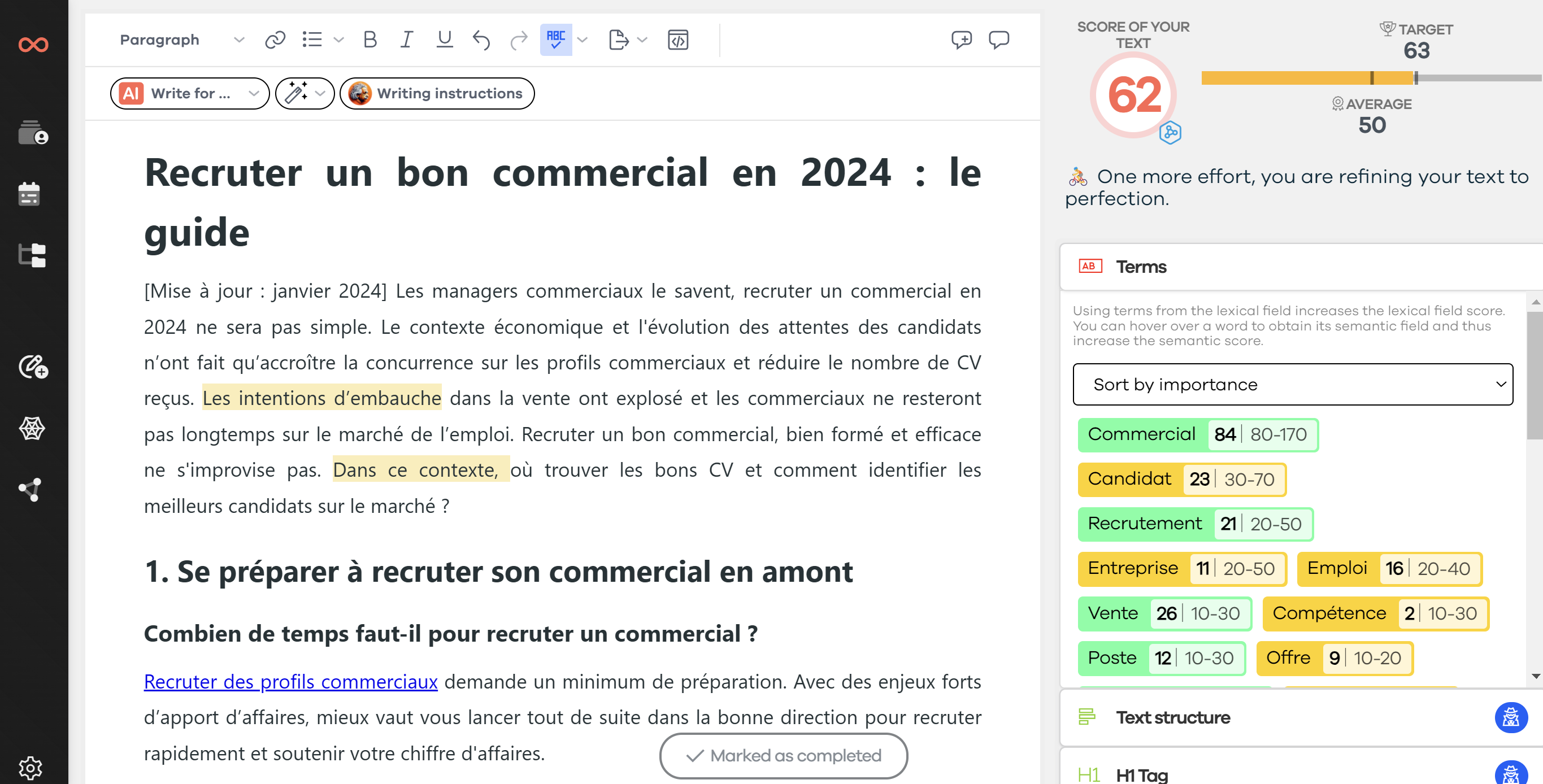
Nossa ferramenta de verificação de relevância de conteúdo
A inteligência artificial a serviço do conteúdo. Em 2018, surge uma nova geração de modelos de IA, permitindo uma representação das palavras não apenas com base em seu contexto geral (as palavras com as quais são frequentemente usadas no corpus de treinamento), mas também com base em seu contexto local (em uma frase específica). Este é o caso do modelo chamado ELMo.

No entanto, o ELMo não foi projetado para produzir incorporações lexicais de frases, tivemos que evoluir essa tecnologia.
Desenvolvemos a partir deste modelo uma ferramenta de avaliação da relevância do conteúdo que nos permite obter uma medida precisa da relevância em relação a uma palavra-chave, um tópico ou um conceito específico.
O que são incorporações lexicais?
Mas o que exatamente isso significa?
Em 2013, uma equipe do Google publicou um artigo descrevendo um processo de treinamento de modelos para ensinar um algoritmo a entender como as palavras são representadas em um espaço vetorial. Representar palavras ou frases em um espaço vetorial dessa maneira é o que entendemos por word embedding (incorporações lexicais).
Desde a publicação do artigo, o conceito rapidamente se tornou uma maneira muito popular de representar o conteúdo textual para qualquer tarefa de aprendizado automático no campo da linguagem natural. Ele permitiu expandir os limites a esse respeito. A melhoria das capacidades dos assistentes pessoais virtuais, como Alexa e Google Assistant, está de fato ligada à publicação desta tecnologia.
O termo "espaço vetorial" é uma abordagem matemática para o processamento de linguagem, entendemos aqui como um sistema multidimensional de coordenadas que nos permite modelar a relação das palavras em função do contexto conceitual.
Imagine, por exemplo, que queremos medir a similaridade entre as cinco palavras seguintes:
- Banana
- Kiwi
- Laranja
- Pimentão
- Caranguejo
A medida da similaridade semântica quando o contexto conceitual é muito estreito pode ser feita de forma intuitiva.
Assim, se avaliarmos as similaridades entre esses alimentos, de acordo com sua natureza, podemos considerar que a banana é muito semelhante à laranja e ao kiwi, pois esses três alimentos são frutas. Por outro lado, o pimentão e o caranguejo podem ser considerados menos semelhantes (alimentos salgados).
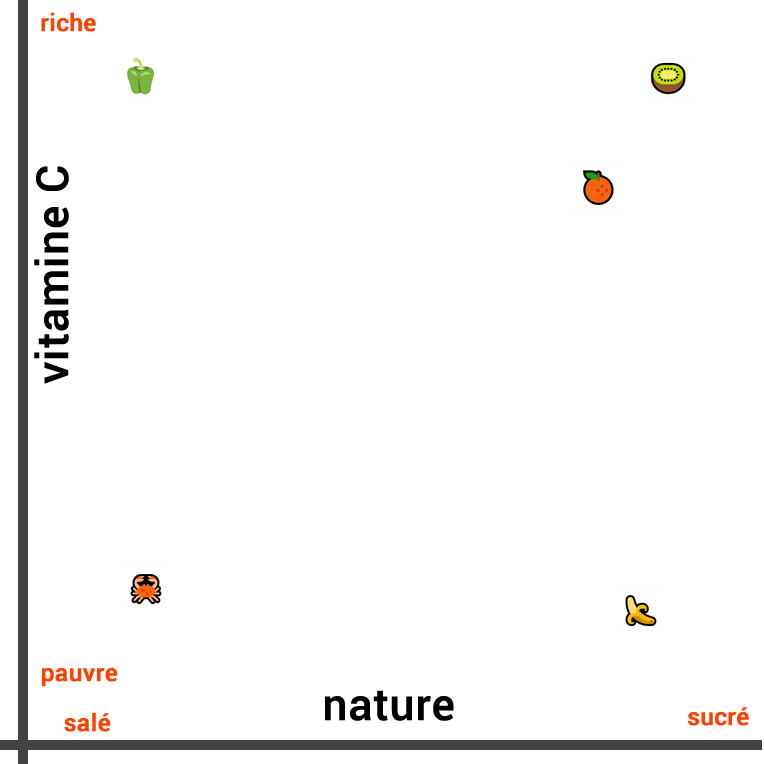
A representação visual de sua similaridade com base em sua natureza é a seguinte:

As três frutas estão próximas umas das outras, enquanto o vegetal está mais distante em uma direção e o caranguejo na direção oposta.
No entanto, quando medimos a similaridade desses alimentos em um contexto diferente, a representação muda completamente. Se nos concentrarmos na composição de vitamina C em vez de sua natureza, o kiwi e o pimentão são semelhantes. Por outro lado, a banana, o caranguejo não são ricos em vitamina C.
Portanto, desta vez, traçamos a seguinte linha:

Também podemos criar uma terceira linha que leva em conta tanto a composição de vitamina C quanto a natureza do alimento (salgado ou doce). Para isso, é necessário representar os dois conceitos em duas dimensões e visualizar a distância entre eles com um traçado em 2D:
Podemos facilmente calcular a distância entre esses pontos usando uma fórmula simples.
Esta é uma representação exata da similaridade geral dessas palavras?
Embora esta terceira representação seja a mais precisa das três, ainda existem outros contextos conceituais a serem considerados. Assim, o caranguejo é um crustáceo, enquanto os outros alimentos não são. Portanto, seria apropriado adicionar uma terceira dimensão. Embora seja possível criar uma representação gráfica em três dimensões, isso ainda é difícil.
Adicionar uma quarta dimensão é quase impossível. ELMo, por outro lado, é capaz de representar o texto em um espaço vetorial de 512 dimensões. É graças à matemática que podemos medir a similaridade entre as palavras em muitas dimensões.
O Word Embedding, portanto, permite obter resultados mais precisos e levar em conta muitos conceitos diferentes. Os algoritmos podem aprender a analisar um grande número de palavras em um espaço altamente dimensional, de modo que obtemos uma representação precisa da "distância" entre as palavras.
Simplificamos os mecanismos para tornar nossa explicação mais clara. A compreensão do embedding de palavras e do aprendizado de linguagem natural é muito mais complexa.
Nos modelos, os "eixos" não representam conceitos discerníveis, como é o caso em nosso exemplo acima. Assim, a medida da similaridade entre as palavras será diferente e é muito provável que os algoritmos estejam interessados no ângulo entre os vetores.
Etapa 1 - Extrair o conteúdo de uma página da Web
Extrair o conteúdo de texto de uma página da web é uma tarefa difícil. Adotar uma abordagem determinista para a extração de conteúdo é impossível. Os humanos, por outro lado, são capazes de fazer isso intuitivamente com muita facilidade. De fato, a maioria das pessoas é capaz de identificar qual texto é importante sem ter que ler o conteúdo da página da Web, graças a pistas visuais, como o layout.
O Google adota um método semelhante em sua abordagem para analisar uma página da Web:
O Google leva em consideração o seu conteúdo não textual e a apresentação visual geral para decidir onde você aparecerá nos resultados de pesquisa. O aspecto visual do seu site nos ajuda a assimilar, a entender suas páginas da Web.
Usando pistas visuais, o Google é melhor capaz de entender o conteúdo que publicamos. Sua compreensão é semelhante à de um humano, pois ele deve ser capaz de fornecer conteúdos que os humanos considerem úteis e relevantes (em vez de um conteúdo que satisfaça ao máximo um modelo de relevância dado).
Como o SEOQuantum extrai o texto de uma página?
Ao desenvolver uma solução que se inspira nesta abordagem, seríamos capazes de criar uma ferramenta escalável que resista ao teste do tempo. Portanto, decidimos abordar a tarefa usando aprendizado de máquina.
Reunimos um grande número de páginas da web para criar um conjunto de dados. A partir deste conjunto, treinamos uma rede neural para extrair as informações de conteúdo.
Treinamos esta ferramenta para analisar vários elementos de cada bloco de texto (como seu tamanho, sua localização na página da web, o tamanho do texto, a densidade do texto, etc.) bem como a imagem da página inteira (por exemplo, o layout visual e as características que os humanos e o Google levam em conta).
Agora temos uma ferramenta confiável capaz de prever a probabilidade de um bloco de texto específico ser considerado parte do conteúdo da página da web.

Agregação de várias seções de conteúdo
Em seguida, tivemos que agregar os resultados de cada bloco de texto em uma nota levando em conta as ponderações relativas à importância de cada bloco.
Existem duas maneiras diferentes de fazer isso:
- Calcular as médias ponderadas de todas as passagens e depois medir suas distâncias em relação à palavra-chave alvo
- Calcular a distância entre cada bloco e a palavra-chave, depois fazer uma média ponderada de todas as distâncias.
Essas duas opções não medem a mesma coisa. A primeira mede a distância entre o "conteúdo médio" e o termo de pesquisa, enquanto a segunda mede a distância média entre cada elemento de conteúdo e a palavra-chave.
Imagine que tenhamos extraído de uma página da web quatro blocos de texto que, uma vez incorporados em nosso espaço vetorial.
O primeiro método consiste em calcular a posição média de todo o conteúdo incorporado, e depois medi-la em relação à incorporação dos termos de pesquisa:
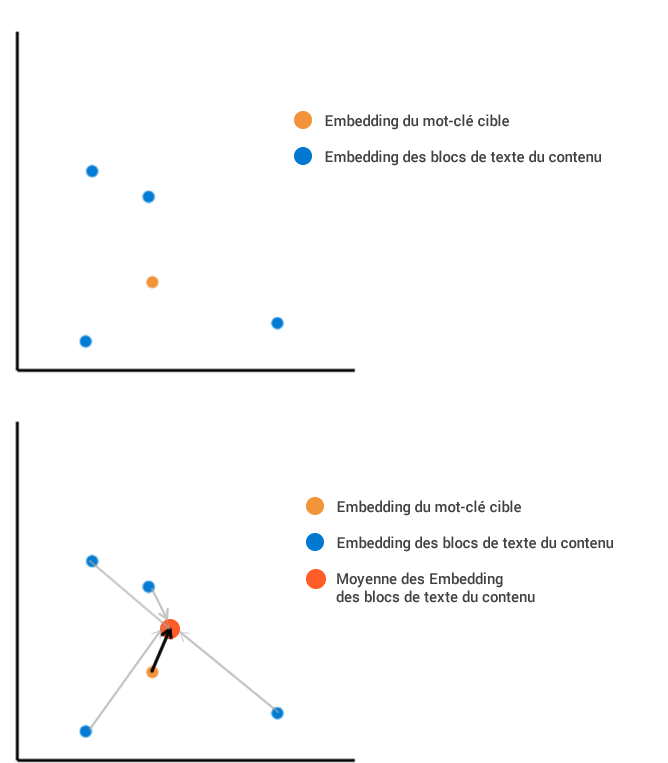
O segundo método consiste em calcular a distância de cada bloco em relação ao termo de pesquisa. Em seguida, fazemos a média de todos esses diferentes comprimentos, o que resulta em um resultado diferente. Neste exemplo, a distância média do comprimento é muito maior com o segundo método do que com o primeiro.
Etapa 2 - Medir a relevância do conteúdo?
O primeiro método tenta agregar todo o conteúdo da página em um único ponto, independentemente da diversidade dos blocos de conteúdo individuais em relação uns aos outros, enquanto o segundo penaliza o conteúdo que é diversificado e menos centrado no termo de pesquisa (mesmo que a agregação desse conteúdo esteja muito próxima do termo de pesquisa). Como cada método fornece um resultado diferente em termos de distância, qual devemos usar?
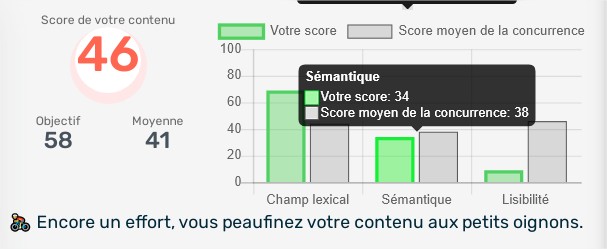
O primeiro método é o mais próximo do que queremos medir, ou seja, a relevância geral do conteúdo. O segundo método consiste em examinar o grau de precisão do conteúdo, o que também pode ser útil. Decidimos que nossa ferramenta de relevância de conteúdo (Score Semântico da ferramenta) deveria medir esses dois elementos e escolhemos usar o primeiro método para medir a relevância geral e o segundo para medir a precisão do conteúdo.
Usando conceitos de normalização para converter distâncias em porcentagem (onde 100% representam uma distância nula e 0% uma distância infinitamente grande), podemos medir tanto a distância de relevância quanto a distância de precisão do conteúdo de uma página da web.
Ter duas notas nos permite avaliar a utilidade do conteúdo caso a caso, levando em conta o tópico e os termos de pesquisa. Seria lógico querer obter duas notas tão altas quanto possível, no entanto, uma pontuação de precisão muito alta nem sempre é necessária. De fato, a precisão de um conteúdo variará dependendo da intenção do usuário. Por exemplo, um usuário que pesquisa a expressão "Yoga" pode estar procurando informações sobre aulas de Yoga e sobre os benefícios do Yoga, caso em que o conteúdo que ele deseja ler não é restrito.
Por que usar nossa ferramenta de otimização de conteúdo?
Nossa ferramenta está disponível gratuitamente em freetrial, então você pode medir a relevância do seu conteúdo web de forma independente.
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: