Foreword: In the world of SEO tools, competition is fierce. Many detractors, colleagues, competitors advance on the methods, technologies used by the SEOQuantum platform without knowing our algorithms. This article lifts the veil on part of our industrial secret. Enjoy :-)
Creating quality and relevant content regarding the keywords you want to rank for is essential. The relevance of the content, however, is more difficult to assess. The era when you could fool a search engine into believing that the content was related to a topic by filling the pages and tags with as many keywords, co-occurrences, and synonyms as possible is over.
Google is continually improving its ability to understand human behavior and language. The search engine's ability to understand and analyze user search intents is better than ever. It is therefore crucial to improve our ability to measure relevance in order to create content that Google perceives as genuinely useful, and therefore more worthy of being well referenced.
Our Content Relevance Verification Tool
Artificial intelligence at the service of content. In 2018, a new generation of AI models appeared, allowing a representation of words not only based on their general context (the words with which they are frequently used in the training corpus), but also based on their local context (in a particular sentence). This is notably the case of the model called ELMo.

ELMo, however, is not designed to produce lexical embeddings of sentences, so we had to evolve this technology.
We have developed from this model a content relevance evaluation tool that allows us to obtain a precise measure of relevance in relation to a given keyword, topic, or concept.
What are lexical embeddings?
But what exactly does this mean?
In 2013, a team from Google published an article describing a process of training models to teach an algorithm to understand how words are represented in a vector space. Representing words or phrases in a vector space in this way is what we mean by word embedding (lexical embeddings).
Since the publication of the article, the concept has quickly become a very popular way of representing textual content for any machine learning task in the field of natural language. It has pushed the boundaries in this regard. The improvement of the capabilities of virtual personal assistants such as Alexa and Google Assistant is indeed linked to the publication of this technology.
The term "vector space" is a mathematical approach to language processing, we understand it here as a multidimensional coordinate system that allows us to model the relationship of words according to the conceptual context.
Let's imagine, for example, that we want to measure the similarity between the following five words:
- Banana
- Kiwi
- Orange
- Pepper
- Crab
The measure of semantic similarity when the conceptual context is very narrow can be done intuitively.
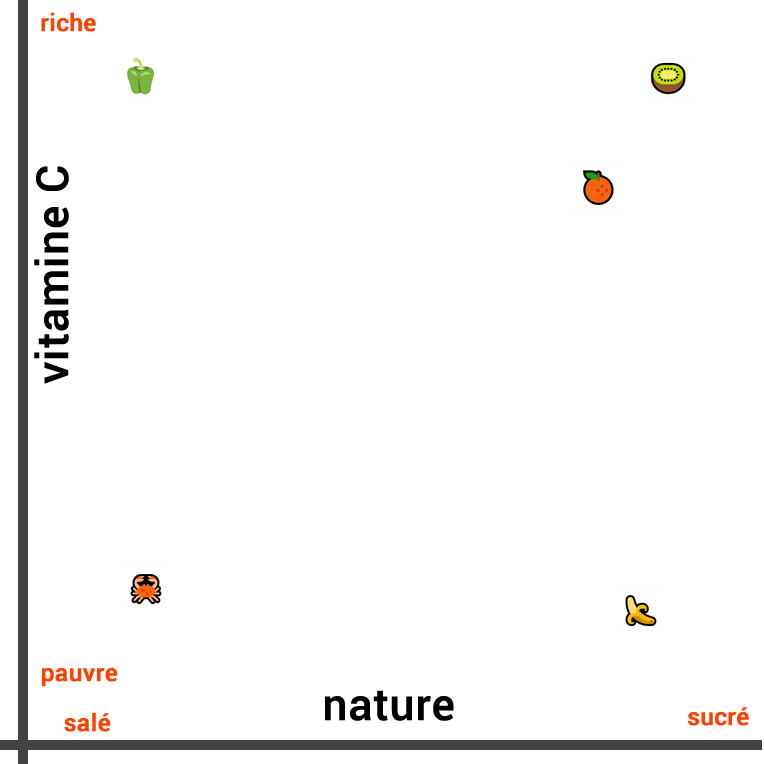
Thus, if we evaluate the similarities between these foods, based on their nature, we can consider that the banana is very similar to the orange and the kiwi, because these three foods are fruits. On the other hand, the pepper and the crab can be considered as being less similar (salty foods).
The visual representation of their similarity based on their nature looks like this:

The three fruits are close to each other while the vegetable is further away in one direction and the crab in the opposite direction.
However, when we measure the similarity of these foods in a different context, the representation changes completely. If we are interested in the vitamin C composition rather than their nature, the kiwi and the pepper are similar. On the other hand, the banana, the crab are not rich in vitamin C.
So, this time, we draw the following line:

We can also create a third line that takes into account both the vitamin C composition and the nature of the food (salty or sweet). To do this, we need to represent the two concepts in two dimensions and visualize the distance between them with a 2D plot:
We can easily calculate the distance between these points using a simple formula.
Is this an accurate representation of the general similarity of these words?
Although this third representation is the most accurate of the three, there are still other conceptual contexts to consider. Thus the crab is a crustacean while the other foods are not. It would therefore be wise to add a third dimension. While it is possible to create a three-dimensional graphical representation, this remains difficult.
Adding a fourth dimension is almost impossible. ELMo, on the other hand, is capable of representing text in a 512-dimensional vector space. It is thanks to mathematics that we can measure the similarity between words on many dimensions.
Word Embedding therefore allows us to obtain more accurate results and to take into account many different concepts. Algorithms can learn to analyze a large number of words in a highly dimensional space, so we get an accurate representation of the "distance" between words.
We have simplified the mechanisms to make our explanation clearer. Understanding word embedding and natural language learning is much more complex.
In the models, the "axes" do not represent discernible concepts as is the case in our example above. Thus, the measure of similarity between words will be different and there is a good chance that the algorithms will be interested in the angle between the vectors.
Step 1 - Extract the content of a web page
Extracting the text content of a web page is a daunting task. Adopting a deterministic approach to content extraction is impossible. Humans, on the other hand, are able to do it intuitively very easily. Indeed, most people are able to identify which text is important without having to read the content of the web page thanks to visual cues such as layout.
Google adopts a similar method in its approach to analyzing a web page:
Google takes into account your non-text content as well as the overall visual presentation to decide where you will appear in the search results. The visual aspect of your website helps us assimilate, understand your web pages.
By using visual cues, Google is better able to understand the content we publish. Its understanding is similar to that of a human, as it must be able to provide content that humans find useful and relevant (rather than content that best satisfies a given relevance model).
How does SEOQuantum extract the text from a page?
By developing a solution that is inspired by this approach, we would be able to create a scalable tool that stands the test of time. We therefore decided to approach the task using machine learning.
We gathered a large number of web pages to constitute a data set. From this set, we trained a neural network to extract content information.
We trained this tool to analyze several elements of each text block (such as its size, its location on the web page, the size of the text, the density of the text, etc.) as well as the image of the entire page (for example the visual layout and the characteristics that humans and Google take into account).
We now have a reliable tool capable of predicting the probability that a given text block is considered part of the content of the web page.

Aggregation of several content sections
We then had to aggregate the results of each text block into a score taking into account the relative weights of the importance of each block.
There are two different ways to do this:
- Calculate the weighted averages of all passages and then measure their distances from the targeted keyword
- Calculate the distance between each block and the keyword, then make a weighted average of all the distances.
These two options do not measure the same thing. The first measures the distance between the "average content" and the search term, while the second measures the average distance between each piece of content and the keyword.
Imagine that we have extracted from a web page four text blocks that, once embedded in our vector space.
The first method consists of calculating the average position of all the embedded contents, then measuring it against the embedding of the search terms:
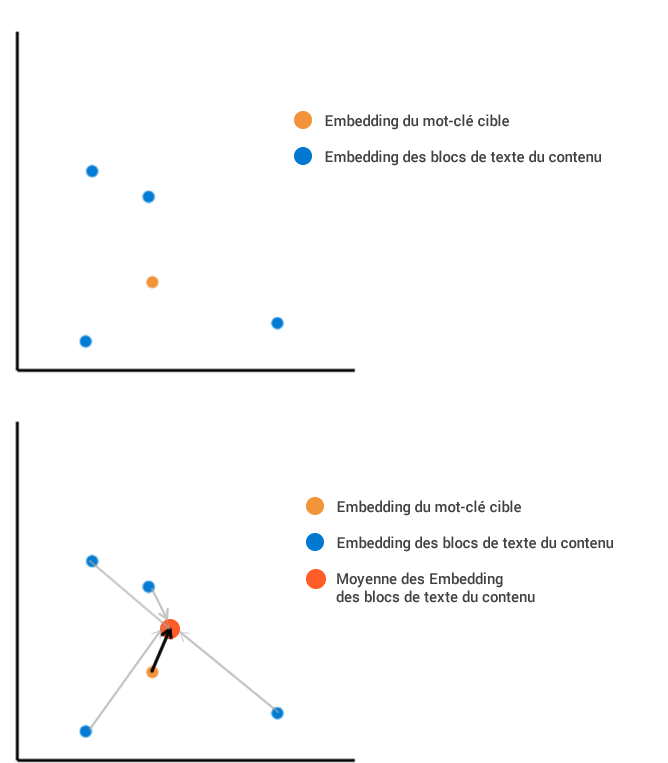
The second method consists of calculating the distance of each block from the search term. We then average all these different lengths, which gives a different result. In this example, the average length distance is much larger with the second method than with the first.
Step 2 - Measure the relevance of the content?
The first method tries to aggregate all the content on the page into a single point, regardless of the diversity of the individual content blocks relative to each other, while the second penalizes content that is diversified and less focused on the search term (even if the aggregation of this content is very close to the search term). Since each method gives a different result in terms of distance, which one should we use?
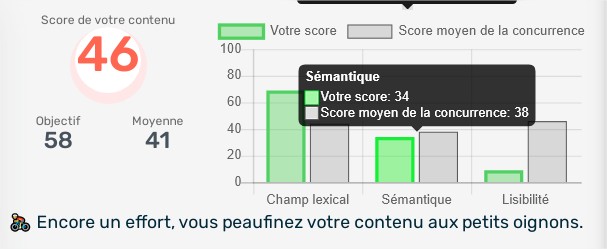
The first method is the closest to what we want to measure, namely the overall relevance of the content. The second method is to examine the degree of precision of the content, which can also be useful. We decided that our content relevance tool (Semantic Score of the tool) should measure these two elements and chose to use the first method to measure overall relevance and the second to measure content accuracy.
By using normalization concepts to convert distances into percentages (where 100% represents a zero distance and 0% an infinitely large distance), we can measure both the relevance distance and the precision distance of a web page's content.
Getting two scores allows us to evaluate the usefulness of the content on a case-by-case basis, taking into account the subject and search terms. It would make sense to want to get two scores as high as possible, yet a too high precision score is not always necessary. Indeed, the precision of a content will vary depending on the user's intent. For example, a user searching for the term "Yoga" may be looking for information on Yoga classes and the benefits of Yoga, in which case the content they want to read is not restricted.
Why use our Content Optimization Tool?
Our tool is available for free in freetrial, so you can independently measure the relevance of your web content.
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: