Tous les outils d’analyses sémantiques utilisent l’extraction de mots-clés pour créer des guides de rédaction. Utiliser la bonne méthode d’extraction en fonction de l’objectif permet de trouver les termes les plus pertinents pour la rédaction SEO.
L’extraction de mots-clés (également appelée analyse des mots-clés) est une méthode d’étude d’un texte qui consiste à extraire automatiquement les mots et les termes les plus importants. Cela permet de résumer le contenu d’un texte et d’identifier les principaux sujets qui sont abordés.
L’extraction de mots-clés aide les moteurs de recherche à analyser les contenus des pages en ligne. Elle permet de trier l’ensemble des données et de définir les mots qui décrivent le mieux chaque page. Ainsi Google crée des clusters (regroupement) de mots-clés économisant ainsi de nombreuses heures de traitement s’il devait interroger l’intégralité de son index à chaque requête.
L’une des principales tâches du SEO consiste à déterminer quels sont les mots clés stratégiques que nous voulons cibler sur notre site web, afin de pouvoir créer du contenu autour de ces mots clés.
Cet article utilise des exemples et références à l’univers Stargate SG-1 :)

❓ À quoi sert l’extraction de mots-clés en SEO ?
Il existe au moins 3 bonnes raisons de rechercher les mots-clés d’une page !
- Connaître les avis
- Surveiller la concurrence
- Trouver de nouvelles idées
1. Extraire les mots-clés et avis d’une page
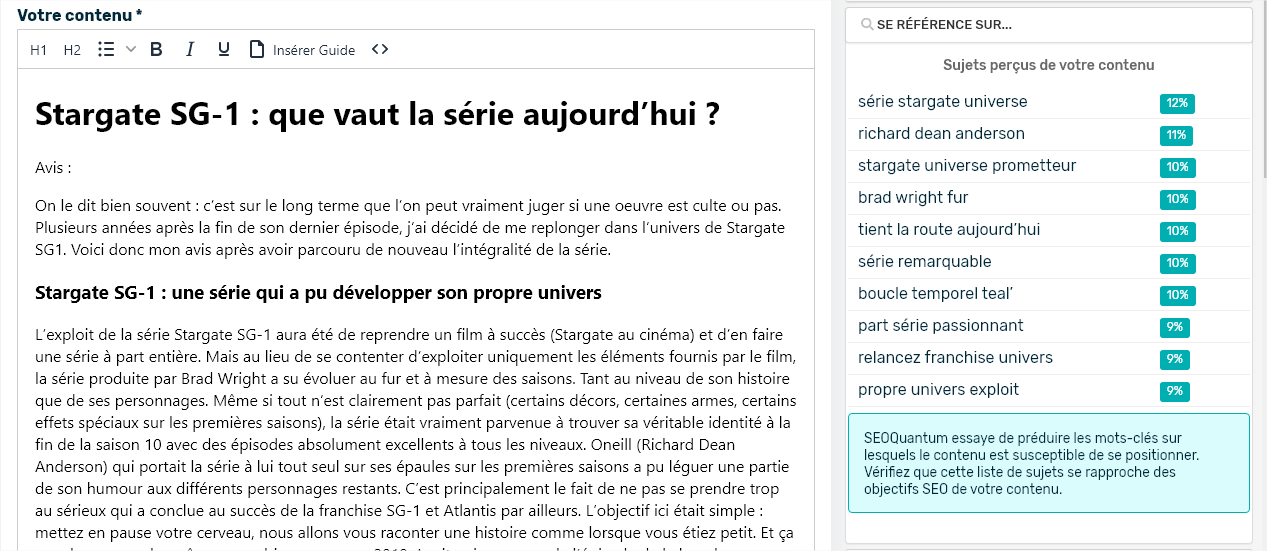
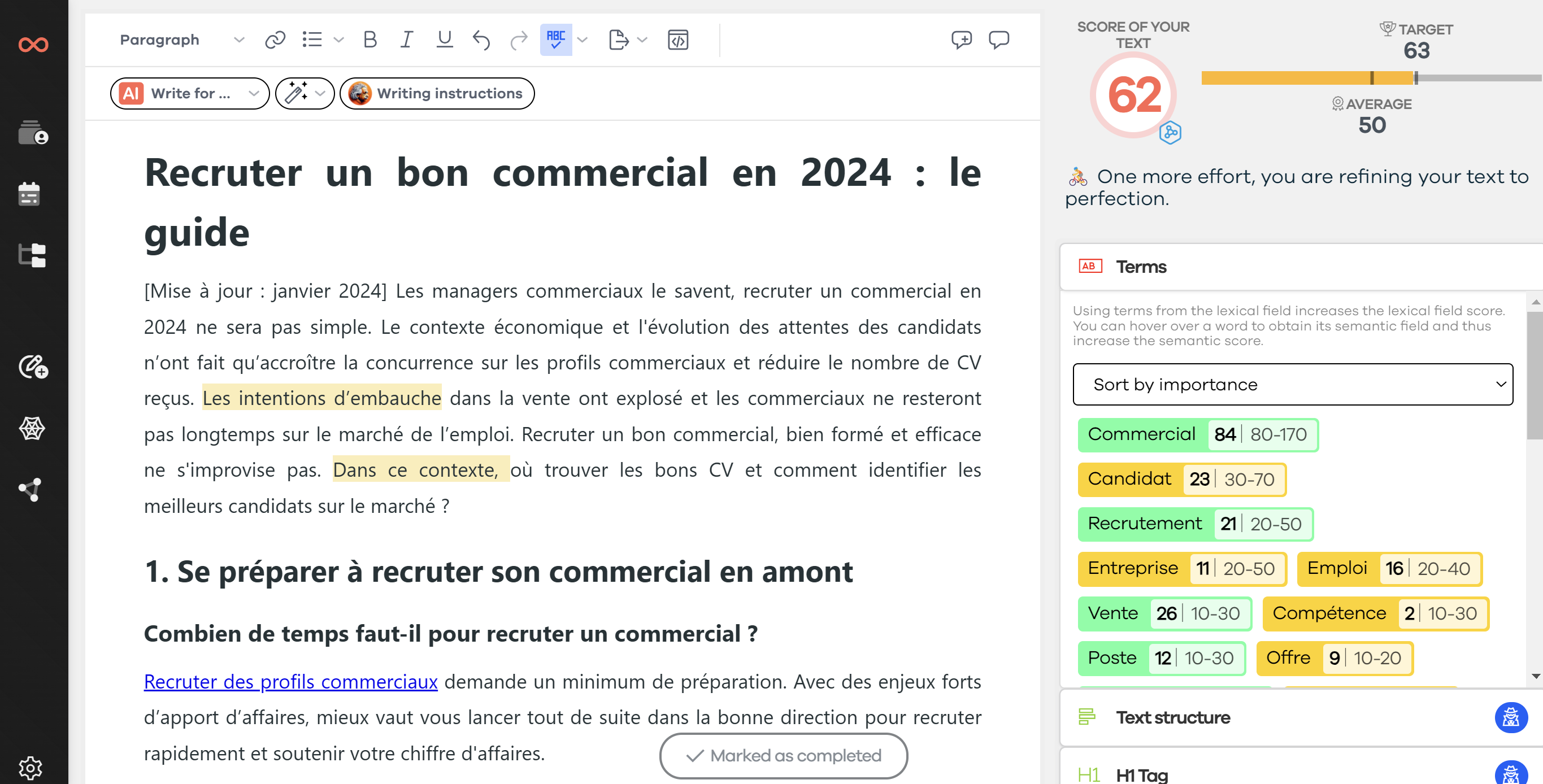
Copie d’écran de l’outil SEOQuantum
Tout d’abord, nous allons étudier l’évaluation d’une page sur la série Stargate. Grâce à l’extraction de mots-clés, il est facile de savoir quels avis sont mentionnés (tient la route ; série remarquable ; prometteur…).
Vous pouvez utiliser le logiciel de SEOQuantum qui permet d’extraire les mots-clés d’un texte pour trouver les mots isolés (mots-clés) ou des groupes de deux ou plusieurs mots qui créent une phrase (phrases clés).
2. Surveiller la concurrence
Il existe une myriade d’outils disponibles pour la recherche de mots clés. Cependant, vous pouvez également profiter de l’extraction de mots clés pour parcourir automatiquement le contenu des sites internet et extraire leurs mots clés les plus fréquents. Si vous identifiez les mots-clés les plus pertinents utilisés par vos concurrents, par exemple, vous pouvez repérer d’excellentes opportunités de rédaction de contenu.
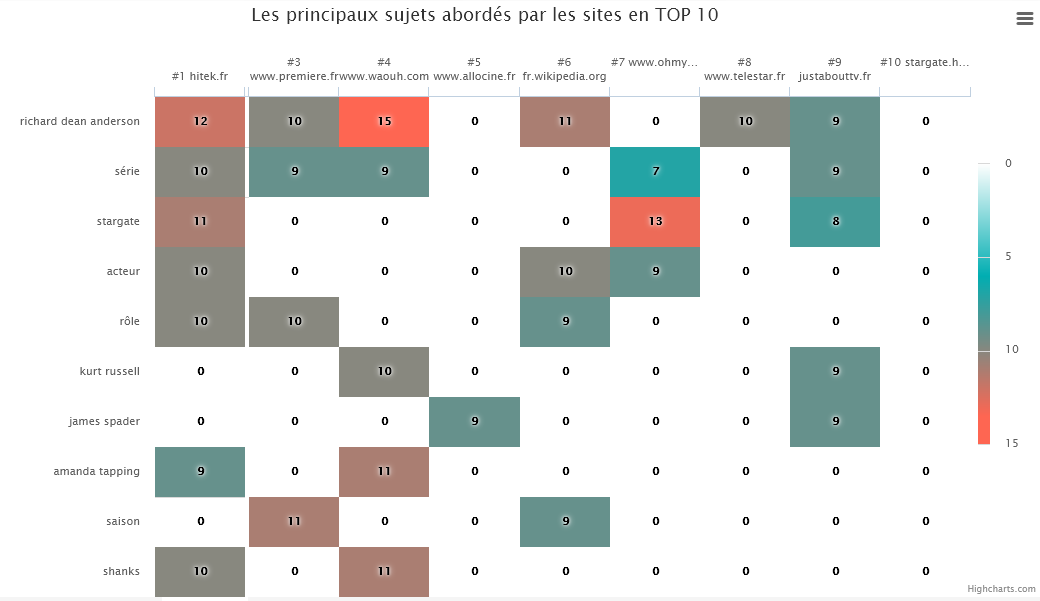
Notamment grâce à l’analyse de la concurrence de SEOQuantum, j’adore ce graphique (heatmap) qui permet de voir en un clin d’œil les sujets abordés par les concurrents sur le TOP 10 de la SERP.
Ici, pour la requête « acteurs stargate », nous notons que :
- Le 1er site positionné aborde principalement la série et les acteurs phare de celle-ci (Richard Dean Anderson, Amanda tapping, Michael Shanks)
- les autres sujets des pages de la SERP sont soit orientées sur la série ou sur les acteurs du premier film (Kurt Russel et James Spader).
En savoir plus sur l’analyse de concurrence SEO.
3. Trouver de nouvelles idées de mots-clés
Les avis sur les produits et d’autres types de contenu généré par les utilisateurs peuvent être d’excellentes sources pour découvrir de nouveaux mots clés. Extraire des mots clés pour identifier les mots clés stratégiques auprès des consommateurs peut être utilisés à des fins de référencement par des stratégies de longue traîne.
Comme vous pouvez le constater, les mots-clés sont déjà présents dans le texte original. C’est la principale différence entre l’extraction de mots-clés et le topic modeling[1], qui consiste à choisir des mots-clés dans une liste de vocabulaire ou à catégoriser un texte en fonction des mots-clés employés.
🤔 En quoi l’extraction de mots-clés est-elle utile ?
Si l’on considère que plus de 80 % des données que nous générons chaque jour ne sont pas structurées — c’est-à-dire qu’elles ne sont pas organisées de manière prédéfinie et qu’elles sont donc difficiles à analyser et à traiter — l’extraction de mots-clés est très attrayante. Il s’agit d’un outil puissant qui peut aider à comprendre les données concernant une page, des avis clients, un commentaire… Bref, toutes données non structurées.
Parmi les grands avantages de l’extraction de mots-clés, on peut notamment citer :
L’évolutivité
L’extraction automatisée de mots-clés vous permet d’analyser autant de données que vous le souhaitez. Certes, vous pourriez lire les textes vous-même et identifier les termes clés manuellement, mais cela prendrait beaucoup de temps. L’automatisation de cette tâche vous donne la liberté de vous concentrer sur d’autres tâches.
Des critères cohérents
L’extraction de mots-clés agit sur la base de règles et de paramètres prédéfinis. Vous n’obtiendrez pas d’incohérences. Ces dernières sont fréquentes lorsque l’analyse du texte est manuelle.
L’analyse en temps réel
Vous pouvez effectuer une extraction de mots-clés sur les publications sur les réseaux sociaux, les avis des clients, ou les tickets de demande d’assistance client et ainsi obtenir des informations sur ce qui se dit sur votre produit en temps réel.
En bref…
L’extraction de mots-clés permet d’extraire ce qui est pertinent d’une grande quantité de données non structurées. En extrayant des mots ou des phrases clés, vous pourrez vous faire une idée des mots les plus importants d’un texte et des sujets abordés.
Maintenant que vous connaissez le concept d’extraction de mots-clés et que vous avez une bonne compréhension de son utilisation, il est temps de comprendre comment il fonctionne. La section suivante explique les principes fondamentaux de l’extraction des mots-clés et vous présente les différentes approches de cette méthode, dont les statistiques, la linguistique et l’apprentissage automatique.
🔎 Comment fonctionne l’extraction de mots-clés ?
L’extraction de mots-clés permet d’identifier facilement les mots et les phrases pertinentes d’un texte non structuré. Cela inclut les pages web, les courriels, les publications sur les réseaux sociaux, les conversations de messagerie instantanée ainsi que tout autre type de données qui n’est pas organisé de manière prédéfinie.
Il existe différentes méthodes que vous pouvez utiliser pour extraire automatiquement les mots-clés. Des approches statistiques simples qui détectent les mots-clés en comptant la fréquence des mots, aux approches plus avancées rendues possibles par l’apprentissage automatique, vous pourrez mettre en place le modèle qui correspond à vos besoins.
Dans cette section, nous allons examiner les différentes approches de l’extraction des mots-clés, en mettant l’accent sur les modèles basés sur l’apprentissage automatique.[2]
Les approches statistiques simples
L’utilisation de statistiques est l’une des méthodes les plus simples pour identifier les mots et les expressions clés d’un texte.
Il existe différents types d’approches statistiques, notamment la fréquence des mots, les collocations de mots et les cooccurrences, le TF-IDF (de l’anglais term frequency-inverse document frequency), et le RAKE (Rapid Automatic Keyword Extraction).
Ces approches ne nécessitent pas de données d’apprentissage pour extraire les mots-clés les plus importants d’un texte. Cependant, puisqu’elles se basent sur les statistiques, elles peuvent négliger des mots ou des phrases pertinentes qui ne sont mentionnés qu’une fois. Examinons plus en détail ces différentes approches :
La fréquence des mots
La fréquence des mots consiste à lister les mots et les phrases qui figurent le plus souvent dans un texte. Cela peut être très utile à de multiples fins, de l’identification des termes récurrents dans une série d’évaluations de produits jusqu’à la recherche des problèmes les plus courants dans les interactions avec le service client.
Cependant, les approches qui se basent sur la fréquence des mots considèrent les documents comme une simple « collection de mots », laissant de côté les aspects cruciaux liés à la sémantique, à la structure, à la grammaire et à l’ordre des mots. Les synonymes, par exemple, ne peuvent pas être détectés par cette méthode.
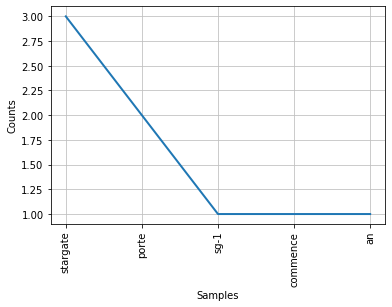
Voici un extrait du code Python pour obtenir la fréquence des mots dans un texte (vous retrouvez le notebook plus bas) :
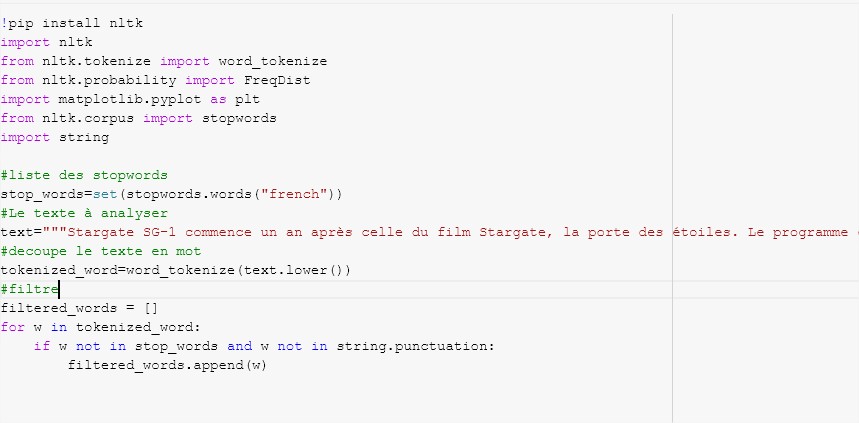

Collocations et cooccurrences de mots
Également connues sous le nom de n-gramme, les collocations de mots et les cooccurrences peuvent vous aider à comprendre la structure sémantique d’un texte. Ces méthodes considèrent chaque mot comme unique.
Différences entre collocations et cooccurrences :
Les collocations sont des mots qui sont souvent associés. Les types de collocations les plus courants sont les bigrammes (deux termes qui apparaissent de manière adjacente, comme « rédaction web » ou encore « agence digitale ») et les trigrammes (un groupe de trois mots, comme « facile à utiliser » ou « transport en commun »).
Les cooccurrences, en revanche, font référence à des mots qui ont tendance à coexister dans le même texte. Elles ne doivent pas nécessairement être adjacentes, mais elles ont une relation sémantique.

Le TF-IDF
TF-IDF est l’abréviation de l’anglais frequency–inverse document frequency, une formule qui mesure l’importance d’un mot apparaissant dans un document faisant partie d’un corpus. Cette mesure calcule le nombre de fois qu’un mot apparaît dans un texte (term frequency) et le compare à l’inverse de la proportion de documents du corpus qui contiennent le terme (soit la rareté ou la fréquence de ce mot).
En multipliant ces deux quantités, on obtient un score TF-IDF. Plus le score est élevé, plus le mot est pertinent pour le document.
En ce qui concerne l’extraction des mots-clés, cette mesure peut vous aider à identifier les mots les plus pertinents d’un contenu (ceux qui ont obtenu les meilleurs scores) et à les considérer comme des mots-clés. Cela peut être particulièrement utile pour des tâches telles que le balisage des tickets de support technique ou l’analyse des commentaires des clients.
Dans la plupart de ces cas, les mots qui apparaissent le plus souvent dans un ensemble de documents ne sont pas nécessairement les plus pertinents. De même, un mot qui apparaît dans un texte unique, mais qui n’apparaît pas dans les autres documents peut être très important pour comprendre le contenu de ce texte.
TF IDF pour le SEO ?
Les moteurs de recherche utilisent parfois le modèle TF-IDF en complément d’autres facteurs.
La méthode TF-IDF fournit-elle suffisamment d’informations pour optimiser vos rédactions de contenus ? Pas du tout.
Cette méthodologie a plus de 50 ans et joue un rôle très limité dans le fonctionnement des algorithmes de recherche de Google. Ce n’est pas une technologie de pointe.
Pour en savoir plus, vous pouvez consulter l’article dédié à TF IDF.
RAKE
Le Rapid Automatic Keyword Extraction (RAKE) est une méthode bien connue d’extraction de mots-clés qui utilise une liste de mots vides (stopwords) et de phrases faisant office de « délimiteurs » pour détecter les mots ou phrases les plus pertinents dans un texte.
Prenez le texte suivant comme exemple :
Suite à l’invasion de la base Stargate par des extraterrestres, le colonel Jack O’Neill est appelé à la rescousse. Stargate SG-1, est alors constitué et envoyé à la découverte de tous ces nouveaux mondes.
La première chose que fait la méthode est de diviser le texte en une liste de mots et de supprimer les mots vides de cette liste. Il en résulte une liste contenant ce que l’on appelle des mots de contenu.
Supposons que notre liste de mots-clés et de phrases ressemble à ceci :
stopwords = [suite, de, la, par, des, le, est, pas, si, il, de, vous, à, des, la, l’une, elles, ….]
Notre liste de 8 mots de contenu ressemblera à ceci :
mots_contenu = [Invasion, base, stargate, extraterrestre, colonel, Jack Oneill, appelé, rescousse, Stargate, SG1, constitué, envoyé, découverte, nouveaux, mondes,…] avec pour délimiteur la virgule ou le point.
Ensuite, l’algorithme divise le texte en fonction des phrases et des mots vides pour créer des expressions. Dans notre cas, les phrases clés seraient les suivantes :
Suite à l’invasion de la base Stargate par des extraterrestres, le colonel Jack ONeill est appelé à la rescousse. Stargate SG-1, est alors constitué par le colonel et envoyé à la découverte de tous ces nouveaux mondes.
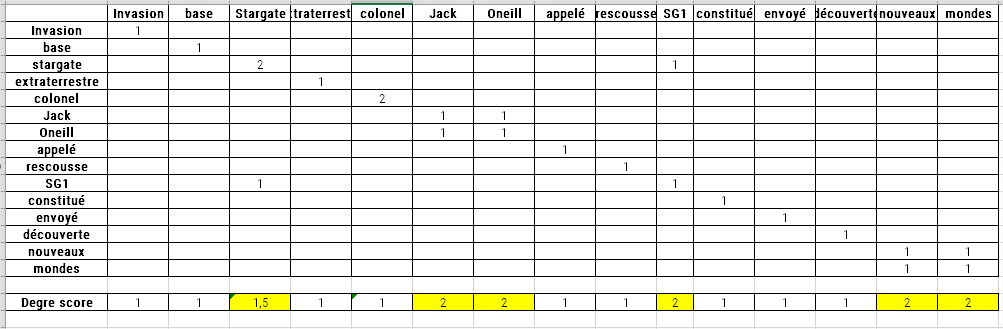
Après avoir ainsi divisé le texte, l’algorithme crée un tableau des cooccurrences de mots. Chaque ligne indique le nombre de fois qu’un mot de contenu donné coexiste avec un autre mot de contenu.
Une fois ce tableau construit, les mots sont notés. Les notes correspondent aux nombres d’apparitions d’un mot dans le tableau (soit la somme du nombre de cooccurrences du mot avec tout autre mot de contenu). Il s’agit donc de la fréquence du mot (c’est-à-dire le nombre de fois que le mot apparaît dans le texte).
Si nous divisons le degré divisé par la fréquence de chacun des mots de notre exemple, nous obtiendrions :
Si deux mots ou phrases clés apparaissent ensemble dans le même ordre plus de deux fois, une nouvelle phrase clé est créée, quel que soit le nombre de mots vides qu’elle contient. La note de cette phrase clé est prise en compte de la même manière que celle des phrases clés uniques.
Un mot-clé ou une phrase clé est sélectionné lorsque sa note fait partie des T meilleures notes, T étant le nombre de mots-clés que vous souhaitez extraire.
Exemple avec RAKE NLTK
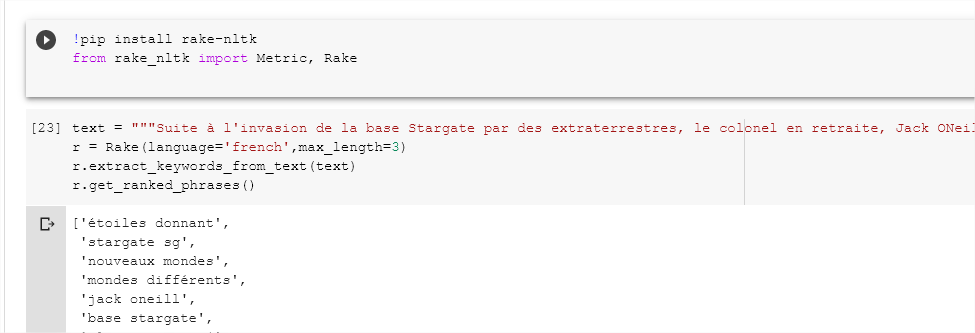
RAKE NLTK est une implémentation Python spécifique de l’algorithme RAKE (Rapid Automatic Keyword Extraction) qui utilise NLTK sous le capot. Cela facilite l’utilisation pour d’autres tâches d’analyse de texte.
Les approches basées sur la théorie des graphes
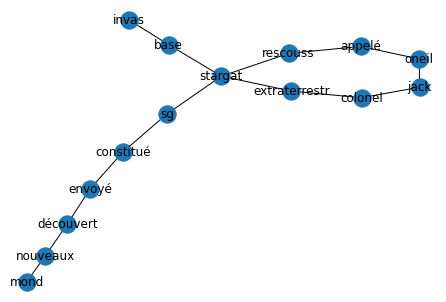
Un graphe peut être défini comme un ensemble de sommets avec des connexions entre eux. Un texte est alors représenté sous forme de graphe de différentes manières. Les mots peuvent être considérés comme des sommets qui sont reliés par un lien dirigé (soit une connexion unidirectionnelle entre les sommets).
Ces liens peuvent qualifier, par exemple, la relation que les mots entretiennent dans un arbre de dépendance. D’autres représentations de documents peuvent utiliser des liens non dirigés, notamment pour représenter des cooccurrences de mots.
Un graphe orienté aurait un aspect un peu différent :
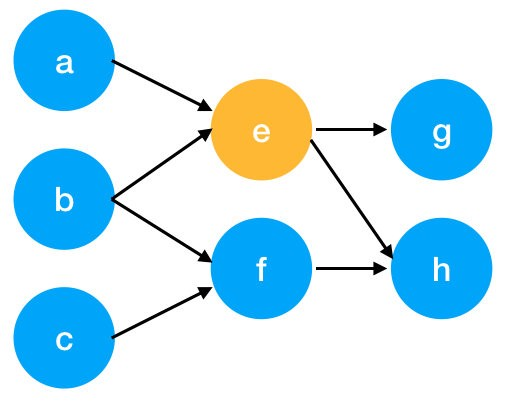
L’idée fondamentale derrière l’extraction de mots-clés par graphe est toujours la même : mesurer l’importance d’un sommet à partir de certaines informations obtenues à partir de la structure du graphe.
Une fois que vous avez créé un graphe, il est temps de déterminer comment mesurer l’importance des sommets. Il existe de nombreuses options. Certaines méthodes choisissent de mesurer ce que l’on appelle le degré d’un sommet (ou valence).
Le degré (ou valence) d’un sommet est égal au nombre de liens ou d’arcs qui sont dirigés vers le sommet et le nombre de liens sortant du somme.
D’autres méthodes mesurent le nombre de sommets immédiats d’un sommet donné ou bien une méthode bien connue dans l’univers du SEO est le calcul du PageRank de ce graphe.
Quelle que soit la mesure choisie, vous obtiendrez une note pour chaque sommet. Cette dernière déterminera s’il doit être choisi comme mot-clé ou non.
Prenez le texte suivant comme exemple :
Suite à l’invasion de la base Stargate par des extraterrestres, le colonel Jack O’Neill est appelé à la rescousse. Stargate SG-1, est alors constitué et envoyé à la découverte de tous ces nouveaux mondes.
🤖 L’apprentissage automatique
Les systèmes qui reposent sur l’apprentissage automatique peuvent être utilisés pour de nombreuses tâches d’analyse de texte, y compris pour l’extraction de mots-clés. Mais qu’est-ce que l’apprentissage automatique ? C’est un sous-domaine de l’intelligence artificielle qui construit des algorithmes capables d’apprendre et de faire des prédictions.[3]
Afin de traiter des données textuelles non structurées, les systèmes d’apprentissage automatique doivent les transformer en quelque chose qu’ils peuvent comprendre. Mais comment y parviennent-ils ? En transformant les données en vecteurs (un ensemble de nombres avec des données codées), qui contiennent les différentes caractéristiques représentatives d’un texte.
Il existe différents algorithmes et méthodes d’apprentissage automatique qui peuvent être utilisés pour extraire les mots-clés les plus pertinents d’un texte, notamment Support Vector Machines(SVM) et le deep learning.
Vous trouverez ci-dessous l’une des approches les plus courantes et les plus efficaces pour l’extraction de mots-clés à l’aide de l’apprentissage automatique :
Les champs aléatoires conditionnels
Les champs aléatoires conditionnels (CRF) constituent une approche statistique qui apprend des modèles en pondérant différentes caractéristiques dans une séquence de mots présents dans un texte. Cette approche tient compte du contexte et des relations entre les différentes variables.
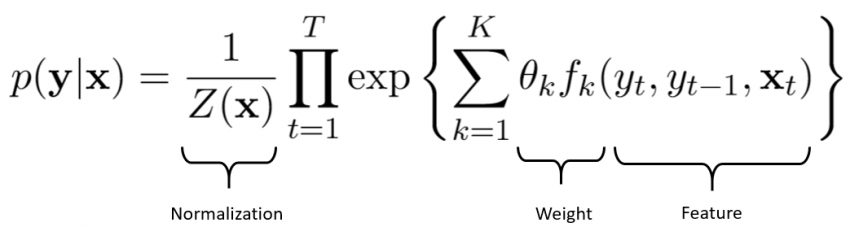
L’utilisation des champs aléatoires conditionnels vous permet de créer des modèles complexes et riches. Un autre avantage de cette approche est sa capacité à synthétiser des informations. En effet, une fois que le modèle a été formé avec des exemples, il peut facilement appliquer ce qu’il a appris à d’autres domaines.
En revanche, pour utiliser les champs aléatoires conditionnels, vous devez avoir de solides compétences mathématiques vous permettant de calculer le pondéré de toutes les caractéristiques, et ce, pour toutes les séquences de mots.
Qu’utilise SEOQuantum pour traiter et extraire les mots-clés ?
Une approche hybride entre Machine Learning, informations linguistiques et statistiques
Les méthodes d’extraction de mots-clés de SEOQuantum font souvent appel à des informations linguistiques. Nous n’allons pas décrire tous les éléments d’information qui ont été utilisés jusqu’à présent, mais en voici quelques-uns.
Parfois, des informations morphologiques ou syntaxiques, telles que le type de mot ou les relations entre les mots dans une représentation grammaticale de dépendance des phrases, sont utilisées pour déterminer quels mots-clés extraire. Dans certains cas, les mots appartenant à certaines classes de mots obtiennent des notes plus élevées (par exemple les noms et les groupes nominaux), car ils contiennent généralement plus d’informations sur les textes que les mots appartenant aux autres catégories.
On utilise des marqueurs discursifs (c’est-à-dire des phrases qui organisent le discours en segments, comme « cependant » ou « de plus ») ou encore des informations sémantiques sur les mots (par exemple les nuances de sens d’un mot donné) avec notamment l’intégration de Word Embedding.
Selon moi, la plupart des outils qui utilisent des informations de type linguistique obtiennent de meilleurs résultats que ceux qui ne les utilisent pas.
Afin d’obtenir de meilleurs résultats lors de l’extraction de mots clés pertinents d’un texte, SEOQuantum utilise donc un concept mixte de traitement linguistique, statistique et machine learning.
Conclusion
Il existe différentes approches pour construire des modèles d’extraction de mots-clés. Des approches statistiques aux modèles basés sur l’apprentissage automatique, nous avons passé en revue toutes les options et fourni un aperçu du fonctionnement de chacune d’entre elles.
La meilleure approche pour vous dépendra de vos besoins, du type de données que vous traiterez et des résultats que vous espérez obtenir.
Maintenant que vous connaissez les différentes options disponibles, il est temps pour vous de mettre ces conseils en pratique et de découvrir toutes les choses passionnantes que vous pouvez faire à l’aide de l’extraction de mots-clés.
L’extraction de mots-clés est un excellent moyen de trouver ce qui est pertinent dans de grands ensembles de données. Cela permet aux personnes travaillant dans toutes sortes de domaines d’automatiser des processus complexes qui, autrement, seraient extrêmement longs et inefficaces (et, dans certains cas, tout simplement impossibles à réaliser manuellement). Cela fournit également des informations précieuses qui peuvent être exploitées pour prendre de meilleures décisions.
Envie de coder par vous-même ? Je vous invite à découvrir ce notebook en Python : https://colab.research.google.com/drive/1Q4yorsQT6eVHmd8H07h7diinQEhCkyng.
🙏 Ressources utilisées pour rédiger cet article
[1] https://fr.wikipedia.org/wiki/Topic_model#:~:text=En%20apprentissage%20automatique%20et%20en,th%C3%A8mes%20abstraits%20dans%20un%20document.
[2] https://hal.archives-ouvertes.fr/hal-00821671/document
[3] https://atlas.irit.fr/PIE/VSST/Actes-VSST2018-Toulouse/Ramiandrisoa.pdf
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: