All semantic analysis tools use keyword extraction to create copywriting guides. Using the right extraction method based on the objective allows you to find the most relevant terms for SEO writing.
Keyword extraction (also called keyword analysis) is a method of studying a text that consists of automatically extracting the most important words and terms. This allows you to summarize the content of a text and identify the main topics being discussed.
Keyword extraction helps search engines analyze the content of online pages. It allows sorting the entire data set and defining the words that best describe each page. Thus, Google creates clusters (groupings) of keywords, saving many processing hours if it had to query its entire index for each request.
One of the main tasks of SEO is to determine which strategic keywords we want to target on our website, in order to create content around these keywords.
This article uses examples and references from the Stargate SG-1 universe :)

❓ What is the purpose of keyword extraction in SEO?
There are at least 3 good reasons to research the keywords of a page!
- Know the opinions
- Monitor the competition
- Find new ideas
1. Extract keywords and opinions from a page
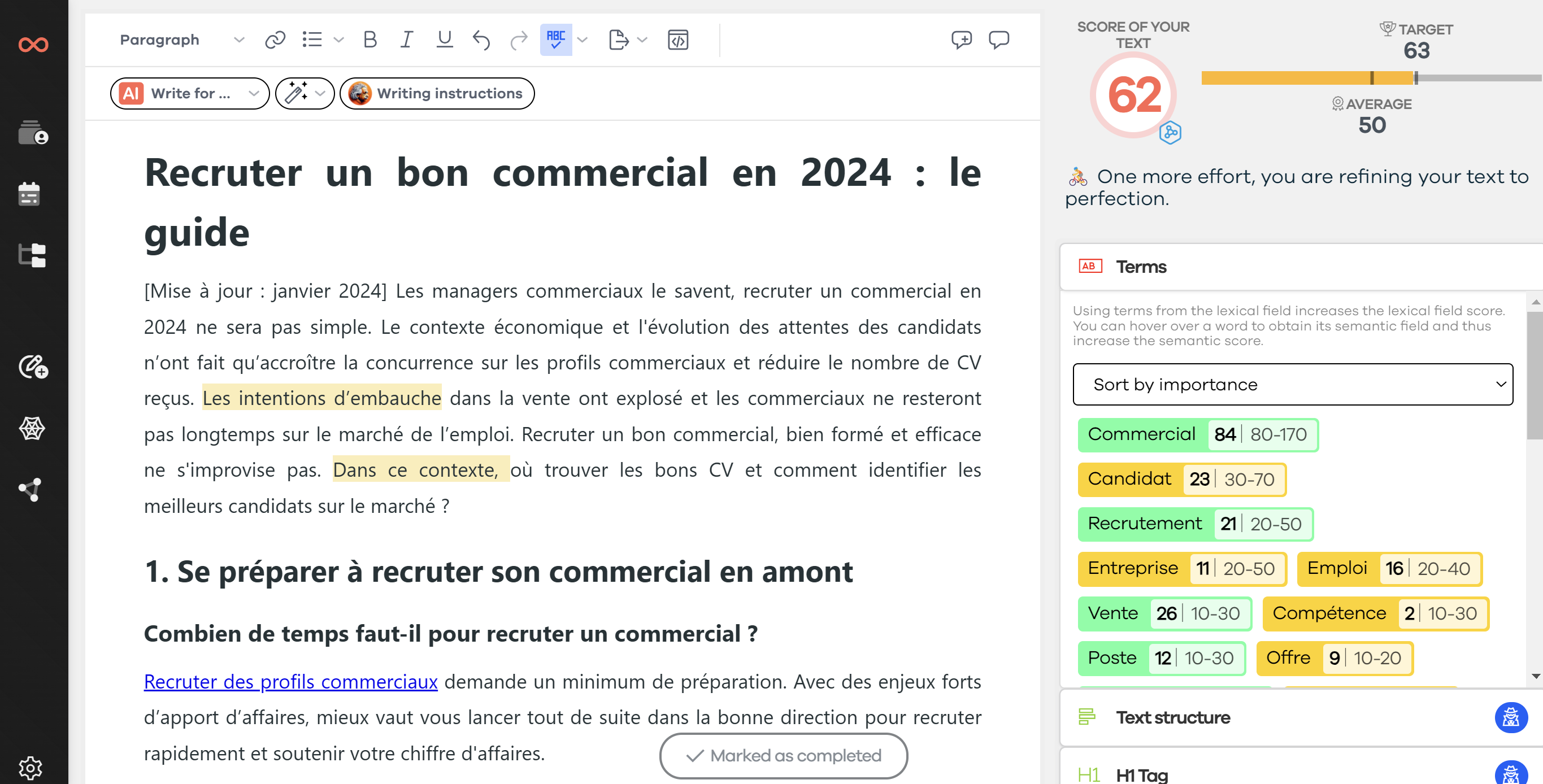
Screenshot of the SEOQuantum tool
First, we will study the evaluation of a page on the Stargate series. Thanks to keyword extraction, it is easy to know which opinions are mentioned (holds up; remarkable series; promising...).
You can use the SEOQuantum software that allows you to extract keywords from a text to find isolated words (keywords) or groups of two or more words that create a sentence (key phrases).
2. Monitor the competition
There is a myriad of tools available for keyword research. However, you can also take advantage of keyword extraction to automatically browse the content of websites and extract their most frequent keywords. If you identify the most relevant keywords used by your competitors, for example, you can spot excellent content writing opportunities.
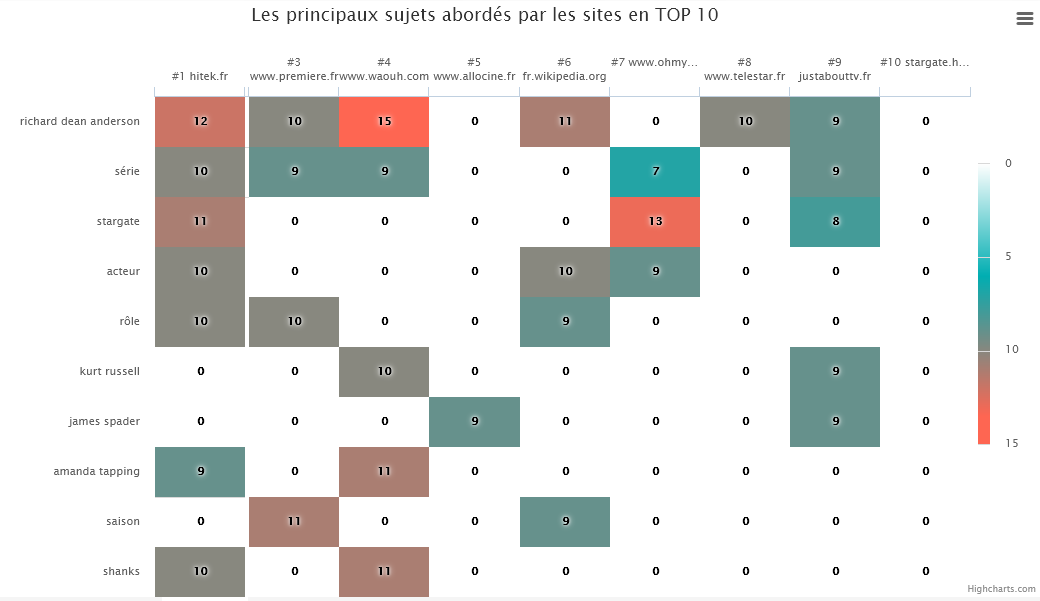
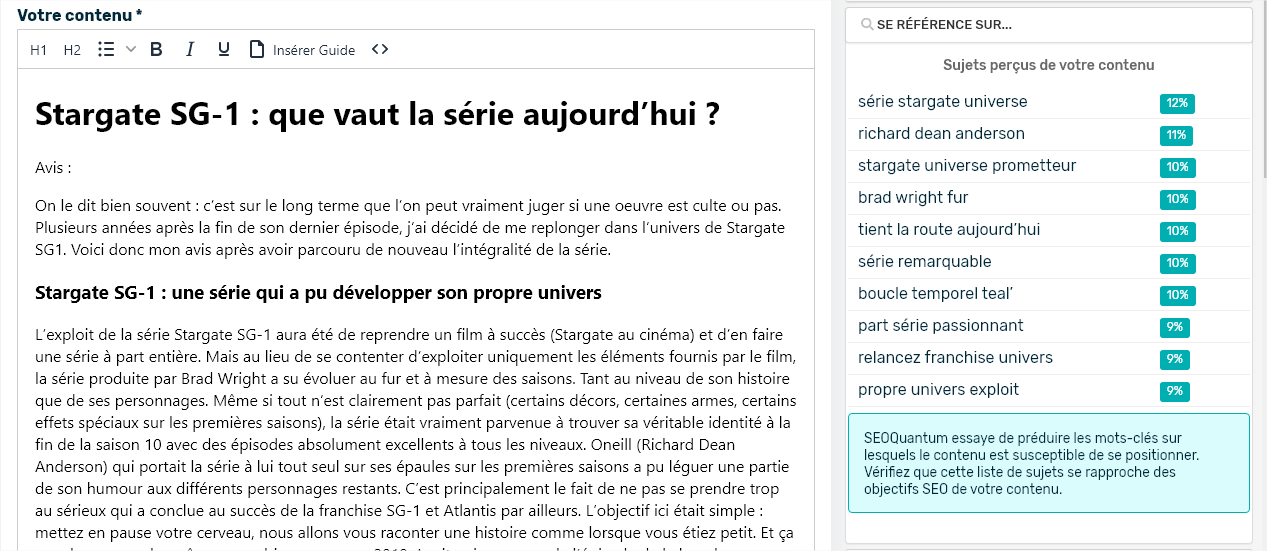
Thanks to SEOQuantum's competition analysis, I love this heatmap that allows you to see at a glance the topics covered by competitors in the TOP 10 of the SERP.
Here, for the query "acteurs stargate", we note that:
- The 1st positioned site mainly deals with the series and its leading actors (Richard Dean Anderson, Amanda Tapping, Michael Shanks)
- The other topics of the SERP pages are either focused on the series or on the actors of the first film (Kurt Russel and James Spader).
3. Find new keyword ideas
Product reviews and other types of user-generated content can be excellent sources for discovering new keywords. Extracting keywords to identify strategic keywords from consumers can be used for SEO purposes through long-tail strategies.
As you can see, the keywords are already present in the original text. This is the main difference between keyword extraction and topic modeling[1], which consists of choosing keywords from a vocabulary list or categorizing a text based on the keywords used.
🤔 How is keyword extraction useful?
Considering that over 80% of the data we generate daily is unstructured - meaning it is not organized in a predefined way and is therefore difficult to analyze and process - keyword extraction is very attractive. It is a powerful tool that can help understand data about a page, customer reviews, a comment... In short, all unstructured data.
Among the major advantages of keyword extraction, we can mention:
Scalability
Automated keyword extraction allows you to analyze as much data as you want. Of course, you could read the texts yourself and identify the key terms manually, but that would take a lot of time. Automating this task gives you the freedom to focus on other tasks.
Consistent criteria
Keyword extraction acts on the basis of predefined rules and parameters. You will not get inconsistencies. These are common when text analysis is manual.
Real-time analysis
You can perform keyword extraction on social media posts, customer reviews, or customer support request tickets and thus obtain information about what is being said about your product in real-time.
In short...
Keyword extraction allows you to extract what is relevant from a large amount of unstructured data. By extracting key words or phrases, you will be able to get an idea of the most important words in a text and the topics covered.
Now that you know the concept of keyword extraction and have a good understanding of its use, it's time to understand how it works. The following section explains the fundamentals of keyword extraction and introduces you to the different approaches to this method, including statistics, linguistics, and machine learning.
🔎 How does keyword extraction work?
Keyword extraction allows you to easily identify relevant words and phrases in unstructured text. This includes web pages, emails, social media posts, instant messaging conversations, and any other type of data that is not organized in a predefined way.
There are different methods you can use to automatically extract keywords. From simple statistical approaches that detect keywords by counting word frequency, to more advanced approaches made possible by machine learning, you can set up the model that suits your needs.
In this section, we will examine the different approaches to keyword extraction, focusing on machine learning-based models.[2]
Simple statistical approaches
Using statistics is one of the simplest methods for identifying key words and phrases in a text.
There are different types of statistical approaches, including word frequency, word collocations and co-occurrences, TF-IDF (term frequency-inverse document frequency), and RAKE (Rapid Automatic Keyword Extraction).
These approaches do not require learning data to extract the most important keywords from a text. However, since they are based on statistics, they may overlook relevant words or phrases that are mentioned only once. Let's take a closer look at these different approaches:
Word frequency
Word frequency consists of listing the words and phrases that appear most often in a text. This can be very useful for multiple purposes, from identifying recurring terms in a series of product evaluations to researching the most common issues in customer service interactions.
However, approaches based on word frequency consider documents as a simple "collection of words," leaving aside crucial aspects related to semantics, structure, grammar, and word order. Synonyms, for example, cannot be detected by this method.
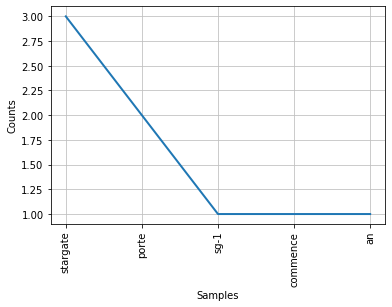
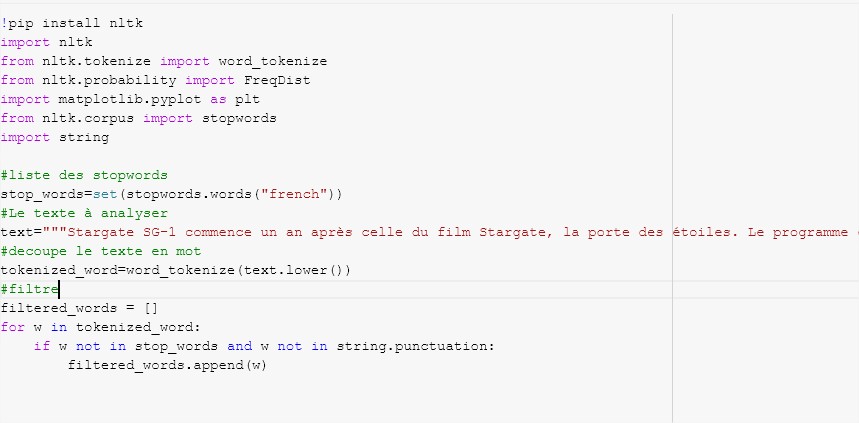
Here is an excerpt of the Python code to get the word frequency in a text (you can find the notebook below):

Collocations and word co-occurrences
Also known as n-grams, word collocations and co-occurrences can help you understand the semantic structure of a text. These methods consider each word as unique.
Differences between collocations and co-occurrences:
Collocations are words that are often associated. The most common types of collocations are bigrams (two terms that appear adjacently, such as "web writing" or "digital agency") and trigrams (a group of three words, such as "easy to use" or "public transportation").
Co-occurrences, on the other hand, refer to words that tend to coexist in the same text. They do not necessarily have to be adjacent, but they have a semantic relationship.

The TF-IDF
TF-IDF is an abbreviation for term frequency-inverse document frequency, a formula that measures the importance of a word appearing in a document that is part of a corpus. This measure calculates the number of times a word appears in a text (term frequency) and compares it to the inverse of the proportion of documents in the corpus that contain the term (i.e., the rarity or frequency of this word).
By multiplying these two quantities, you get a TF-IDF score. The higher the score, the more relevant the word is to the document.
Regarding keyword extraction, this measure can help you identify the most relevant words in content (those that have obtained the best scores) and consider them as keywords. This can be particularly useful for tasks such as tagging technical support tickets or analyzing customer comments.
In most of these cases, the words that appear most often in a set of documents are not necessarily the most relevant. Similarly, a word that appears in a single text but does not appear in other documents can be very important for understanding the content of that text.
TF IDF for SEO?
Search engines sometimes use the TF-IDF model in addition to other factors.
Does the TF-IDF method provide enough information to optimize your content writing? Not at all.
This methodology is over 50 years old and plays a very limited role in the functioning of Google's search algorithms. It is not cutting-edge technology.
RAKE
Rapid Automatic Keyword Extraction (RAKE) is a well-known keyword extraction method that uses a list of stop words and phrases acting as "delimiters" to detect the most relevant words or phrases in a text.
Take the following text as an example:
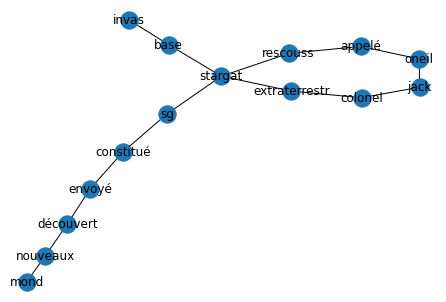
Following the invasion of the Stargate base by aliens, Colonel Jack O'Neill is called to the rescue. Stargate SG-1 is then formed and sent to discover all these new worlds.
The first thing the method does is divide the text into a list of words and remove the stop words from this list. This results in a list containing what are called content words.
Suppose our list of keywords and phrases looks like this:
stopwords = [suite, de, la, par, des, le, est, pas, si, il, de, vous, à, des, la, l’une, elles, ….]
Our list of 8 content words will look like this:
content_words = [Invasion, base, stargate, extraterrestrial, colonel, Jack Oneill, called, rescue, Stargate, SG1, formed, sent, discovery, new, worlds,…] with the delimiter being a comma or period.
Next, the algorithm divides the text based on phrases and stop words to create expressions. In our case, the key phrases would be:
Following the invasion of the Stargate base by aliens, Colonel Jack ONeill is called to the rescue. Stargate SG-1 is then formed by the colonel and sent to discover all these new worlds.
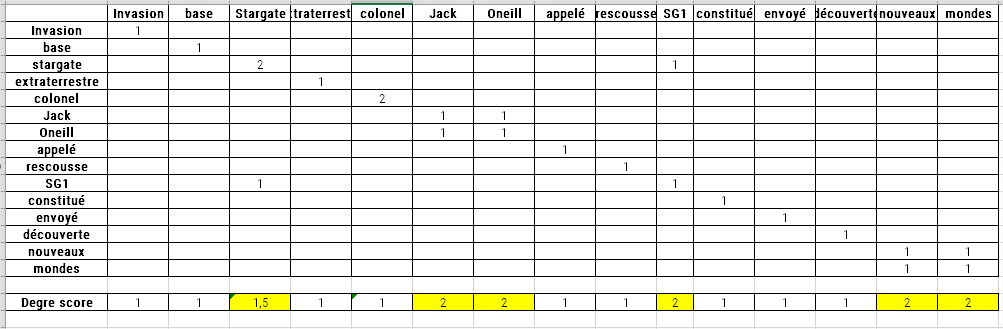
After dividing the text in this way, the algorithm creates a table of word co-occurrences. Each row indicates the number of times a given content word coexists with another content word.
Once this table is built, the words are scored. The scores correspond to the number of appearances of a word in the table (i.e., the sum of the number of co-occurrences of the word with any other content word). This is the word frequency (i.e., the number of times the word appears in the text).
If we divide the degree divided by the frequency of each of the words in our example, we would get:
If two keywords or key phrases appear together in the same order more than twice, a new key phrase is created, regardless of the number of stop words it contains. The score of this key phrase is taken into account in the same way as that of unique key phrases.
A keyword or key phrase is selected when its score is among the T best scores, T being the number of keywords you want to extract.
Example with RAKE NLTK
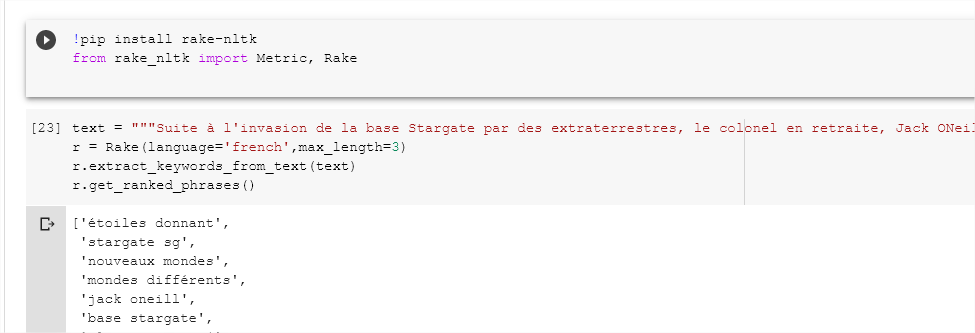
RAKE NLTK is a specific Python implementation of the RAKE (Rapid Automatic Keyword Extraction) algorithm that uses NLTK under the hood. This makes it easy to use for other text analysis tasks.
Graph-based approaches
A graph can be defined as a set of vertices with connections between them. A text is then represented as a graph in various ways. Words can be considered as vertices that are connected by a directed link (i.e., a unidirectional connection between vertices).
These links can qualify, for example, the relationship between words in a dependency tree. Other document representations can use undirected links, notably to represent word co-occurrences.
A directed graph would look slightly different:
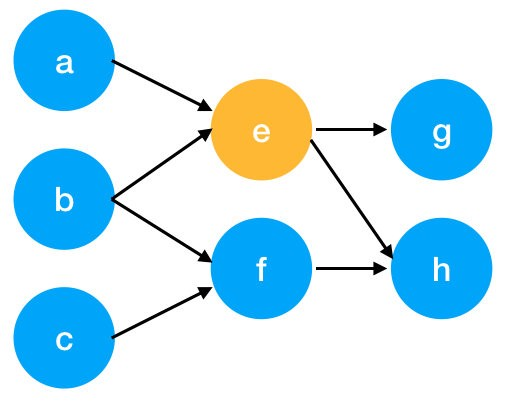
The fundamental idea behind graph-based keyword extraction is always the same: measure the importance of a vertex from certain information obtained from the graph structure.
Once you have created a graph, it is time to determine how to measure the importance of vertices. There are many options. Some methods choose to measure what is called the degree of a vertex (or valence).
The degree (or valence) of a vertex is equal to the number of links or arcs that are directed towards the vertex and the number of links coming out of the vertex.
Other methods measure the number of immediate vertices of a given vertex, or a well-known method in the SEO universe is the calculation of the PageRank of this graph.
Whichever measure is chosen, you will get a score for each vertex. This score will determine whether it should be chosen as a keyword or not.
Take the following text as an example:
Following the invasion of the Stargate base by aliens, Colonel Jack O'Neill is called to the rescue. Stargate SG-1 is then formed and sent to discover all these new worlds.
🤖 Machine learning
Systems based on machine learning can be used for many text analysis tasks, including keyword extraction. But what is machine learning? It is a subfield of artificial intelligence that builds algorithms capable of learning and making predictions.[3]
In order to process unstructured textual data, machine learning systems must transform it into something they can understand. But how do they do this? By transforming the data into vectors (a set of numbers with encoded data), which contain the different representative features of a text.
There are different algorithms and machine learning methods that can be used to extract the most relevant keywords from a text, including Support Vector Machines(SVM) and deep learning.
Below is one of the most common and effective approaches for keyword extraction using machine learning:
Conditional random fields
Conditional random fields (CRF) are a statistical approach that learns models by weighting different features in a sequence of words present in a text. This approach takes into account the context and relationships between different variables.
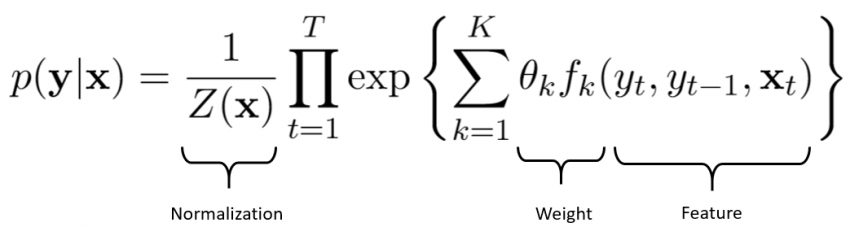
Using conditional random fields allows you to create complex and rich models. Another advantage of this approach is its ability to synthesize information. Indeed, once the model has been trained with examples, it can easily apply what it has learned to other domains.
On the other hand, to use conditional random fields, you must have strong mathematical skills that allow you to calculate the weighted sum of all the features, and this for all word sequences.
What does SEOQuantum use to process and extract keywords?
A hybrid approach between Machine Learning, linguistic information, and statistics
SEOQuantum's keyword extraction methods often use linguistic information. We will not describe all the information elements that have been used so far, but here are a few.
Sometimes, morphological or syntactic information, such as word type or relationships between words in a dependency representation of sentences, is used to determine which keywords to extract. In some cases, words belonging to certain word classes get higher scores (e.g., nouns and noun groups) because they generally contain more information about texts than words belonging to other categories.
We use discourse markers (i.e., phrases that organize discourse into segments, such as "however" or "moreover") or semantic information about words (e.g., nuances of meaning of a given word) with the integration of Word Embedding.
In my opinion, most tools that use linguistic-type information get better results than those that do not.
In order to achieve better results when extracting relevant keywords from a text, SEOQuantum therefore uses a mixed concept of linguistic, statistical, and machine learning processing.
Conclusion
The best approach for you depends on your needs, the type of data you will process, and the results you hope to achieve.
Now that you know the different options available, it's time for you to put these tips into practice and discover all the exciting things you can do with keyword extraction.
Keyword extraction is an excellent way to find what is relevant in large data sets. It allows people working in all kinds of fields to automate complex processes that would otherwise be extremely time-consuming and inefficient (and, in some cases, simply impossible to perform manually). It also provides valuable insights that can be used to make better decisions.
Want to code it yourself? I invite you to discover this Python notebook: https://colab.research.google.com/drive/1Q4yorsQT6eVHmd8H07h7diinQEhCkyng.
🙏 Resources used to write this article
[1] https://fr.wikipedia.org/wiki/Topic_model#:~:text=En%20apprentissage%20automatique%20et%20en,th%C3%A8mes%20abstraits%20dans%20un%20document.
[2] https://hal.archives-ouvertes.fr/hal-00821671/document
[3] https://atlas.irit.fr/PIE/VSST/Actes-VSST2018-Toulouse/Ramiandrisoa.pdf
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: