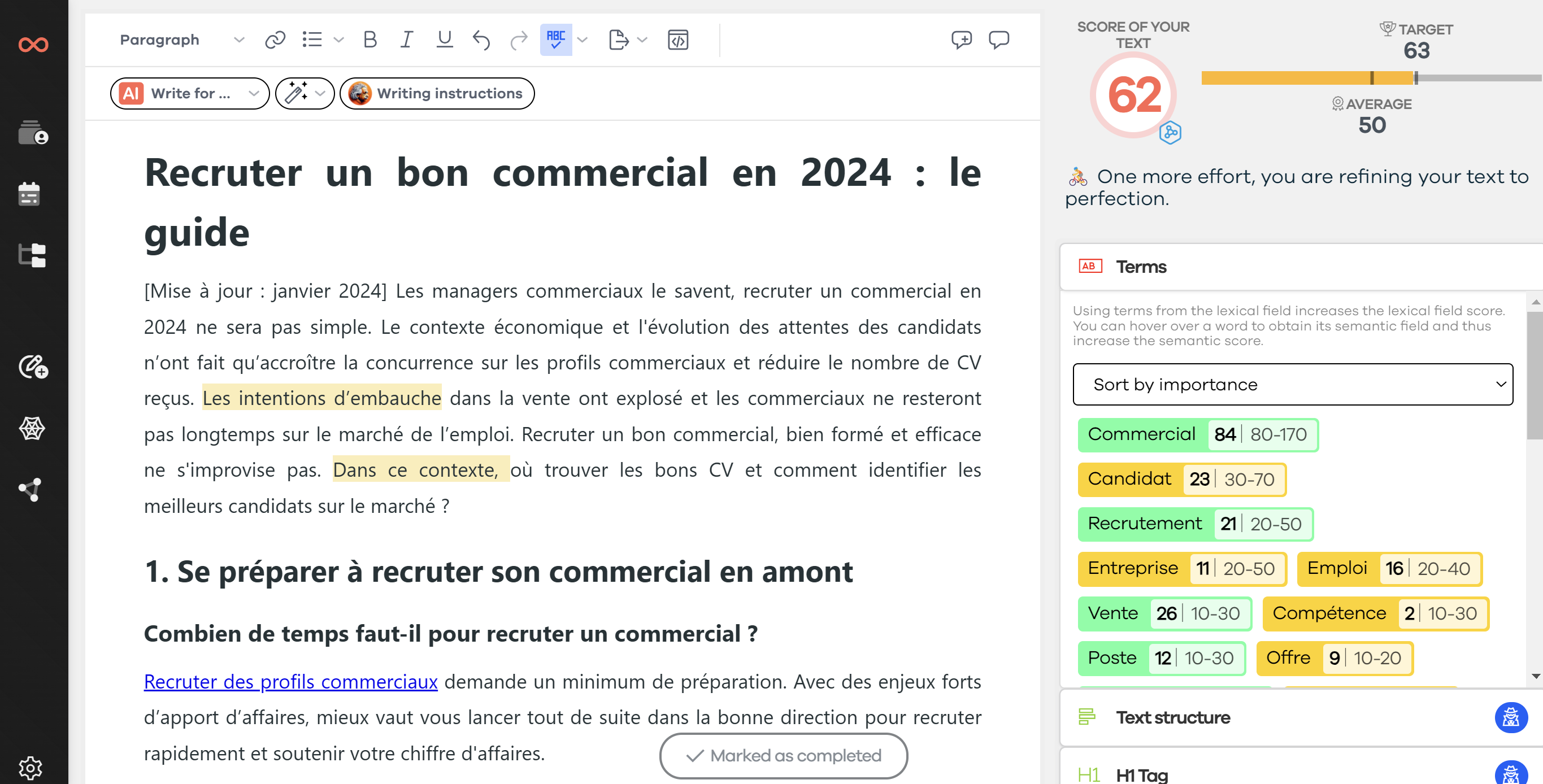
Já se perguntou por que alguns conteúdos curtos estão bem posicionados? Qual é o segredo? Ao conversar com a comunidade SEO, percebo que este tópico frequentemente surge: a extensão dos conteúdos, parece que quanto mais longo, melhor. Tem certeza disso? Alguns consideram os conteúdos longos como o novo Santo Graal do SEO, e tudo isso por causa de estudos que mostram uma correlação entre a extensão do conteúdo e o posicionamento. Vamos descobrir juntos qual é realmente a importância da extensão do conteúdo em SEO e como defini-la.
⚖ Qual é o comprimento ideal de um conteúdo para SEO?
Você fez suas pesquisas na Internet e descobriu que a extensão do conteúdo é crucial para o SEO de suas páginas? Isso é falso! Em si, o número de palavras não é um fator de SEO. O que realmente importa é a qualidade do conteúdo. Isso foi confirmado várias vezes no Twitter por John Muller [1], search advocate do Google. Além disso, Martin Splitt, developer advocate do Google, também confirma isso no vídeo abaixo.
O que confundiu as pessoas foram as muitas estatísticas disponíveis na Internet. Por exemplo, em 2020, a Backlinko anunciou que a média de conteúdos exibidos na primeira página do Google continha 1.447 palavras [2]. Então, todo mundo pensou que precisava escrever pelo menos 1.500 palavras para estar no top 10... Outras análises até mostraram que um copywriter deveria escrever pelo menos 2.000 palavras por conteúdo para aparecer na primeira página dos motores de busca!

Exemplo de estatísticas SEO sobre a relação entre número de palavras e posição
A realidade é que o importante não é o tamanho do conteúdo, mas a sua relevância! É exaustivo e responde à intenção de busca? Se, após a leitura, você responder sim a essas duas perguntas, então sua página está pronta para ser publicada. Quando você trabalha com uma palavra-chave, nunca se esqueça de se colocar no lugar do Googler e tentar entender perfeitamente o que está por trás de uma consulta.
No entanto, você notará que muito poucos resultados exibidos contêm menos de 300 palavras. Por quê? Porque, você concordará, é difícil tratar de um assunto em sua totalidade com um texto tão curto. No entanto, isso depende novamente do tema. Se, por exemplo, você está descrevendo um parafuso de aço inoxidável, então pode ser difícil fazer mais (o primeiro resultado exibido contém apenas 125 palavras!).
O que você precisa lembrar é que não há um comprimento ideal para um conteúdo web! Seu principal objetivo é atender às necessidades do usuário, abordando o assunto de forma completa e detalhada. Para ter uma ideia das expectativas do Google, basta analisar a SERP ou usar a ferramenta de análise semântica do SEOQuantum.
## 🔎 Diferença entre conteúdo e contêiner
Acredito que o conceito de "conteúdo longo" é mal compreendido, confundindo "conteúdo" com "contêiner". Seja um post de blog, um infográfico, um post de convidado, não é o contêiner, mas o conteúdo apresentado nesses tipos de conteúdo que importa. Portanto, se o conteúdo é ruim, não importa o formato... ele continua ruim. O conteúdo longo não será capaz de oferecer os resultados e objetivos que você ou a equipe de marketing estão buscando.
Olivier Andrieu também lembra isso em seu artigo sobre o assunto em 2021 [3]. Ele recomenda, corretamente, que a extensão de um conteúdo SEO seja adaptada ao tipo de formato editorial que você está escrevendo. Em resumo, se você está escrevendo um post de blog, uma página comercial ou um guia de uso, o número de palavras a serem usadas variará consideravelmente.
Claro, o conteúdo longo (pelo menos os bons) visa intencionalmente os usuários que estão procurando informações longas e detalhadas. O tempo de visita ao seu conteúdo é, portanto, maior, a taxa de rejeição é melhor e assim por diante (veja os fatores de classificação do Google). Mas você poderia fazer o mesmo com um conteúdo curto.
## 💞 Correlação não significa causalidade!
Vamos voltar às declarações sobre os estudos de SEO (quanto mais longo o conteúdo, melhor). Uma correlação não significa causalidade: este é um conceito importante, especialmente porque muitos estudos de SEO que você vê são baseados em correlações. Muitos estudos científicos usam correlações para priorizar uma hipótese ou outra. Mas isso não significa que a variável em questão é a causa. Apenas uma correlação. Isso é muito diferente.

É por isso que chamamos de "efeito cegonha" essa tendência de confundir correlação e causalidade.
## 👀 Como um conteúdo curto pode ser visível no Google?
O conteúdo curto deve ser focado em um único problema. O conteúdo é muito direcionado, muitas vezes uma única imagem ou vídeo que explica um único conceito. Você sempre deve tentar simplificar o conteúdo. O conteúdo curto é preciso e focado em um ponto ou conceito específico que atende à intenção do usuário!
O segredo de um bom conteúdo curto que se posiciona:
- Descobrir a intenção dos usuários, responder às suas perguntas e ajudá-los a alcançar seus objetivos
- Fornecer valor agregado
- Propor um conteúdo diferente dos concorrentes (como Oscar Wilde disse "seja você mesmo, os outros já estão ocupados")
- Oferecer uma experiência do usuário diferente, fácil e acessível em todos os dispositivos
A expressão "conteúdo de qualidade" não significa "conteúdo longo". Na verdade, o "bom conteúdo" geralmente não significa nada. Sua definição é subjetiva e específica para cada palavra-chave.
Para cada palavra-chave (ou grupo de palavras-chave) corresponde um tipo de usuário (o avatar), eu costumo determinar os seguintes pontos:
- Que tipo de conteúdo (formato) o usuário usa diariamente? Blog, vídeo, infográfico...
- Que formato agrega valor ao meu conteúdo?
- Como diferenciar meu par formato/conteúdo dos concorrentes?
O problema é que muito poucas pessoas fazem esse tipo de reflexão estratégica. Eles preferem explorar o novo formato da moda, sem se perguntar se o formato é consumido pelo público e se os concorrentes já o usaram.
## 🥇 Em SEO, o conteúdo curto pode vencer!
Em vez de aplicar uma tática sistemática de conteúdo longo onde você define a extensão do conteúdo como o único indicador de qualidade, adapte seu conteúdo às necessidades de seu público e aos seus objetivos comerciais. 300, 500 ou 1.000 palavras a mais não vão ajudá-lo a alcançar seus objetivos de posicionamento mais facilmente.
Crie conteúdo que ajude os usuários. Faça isso de forma eficaz. Escreva para o leitor, nunca escreva um post ou infográfico que transmita pouco valor agregado. Seu público e seu SEO serão muito gratos.
## 🙏 Fontes usadas para escrever este artigo
[1] https://twitter.com/JohnMu/status/1021690796691607552?s=20
[2] https://backlinko.com/search-engine-ranking
[3] https://www.abondance.com/20211115-46571-comment-calculer-la-longueur-dun-contenu-seo.html
Need to go further?
If you need to delve deeper into the topic, the editorial team recommends the following 5 contents: